-- : --
Зарегистрировано — 120 425Зрителей: 63 780
Авторов: 56 645
On-line — 2493Зрителей: 451
Авторов: 2042
Загружено работ — 2 074 314



СОЦИАЛЬНАЯ СЕТЬ ДЛЯ ТВОРЧЕСКИХ ЛЮДЕЙ
«Неизвестный Гений»
самогасимое шифрование
Пред. |
Просмотр работы: |
След. |

В настоящей работе излагается идея шифрования, гасящего статистику знаков, с иллюстрированием модельной программной системой.
Шифрование невернамовское, т.е. основанное не на наложении на шифруемый текст "гаммы". Предлагаемый принцип шифрования основан на том, что для успешного кодирования достаточно обеспечить однозначность именно раскодирования.
Шифрование начинается с этапа генерации ключа. Для этого выбирается достаточно длинный текст естественного языка, содержащий в себе все используемые символы (в примере это буквы, кроме "ё" и "ъ", поскольку во многих текстах их может просто не быть, а также наиболее часто и потому наверняка содержащиеся в выбранном тексте знаки: пробел " ", точка ".", запятая ",", вопросительный знак "?" и скобки "(" и ")"). Последовательность выявленных используемых символов должна быть не меньше 256×256 = 65536.
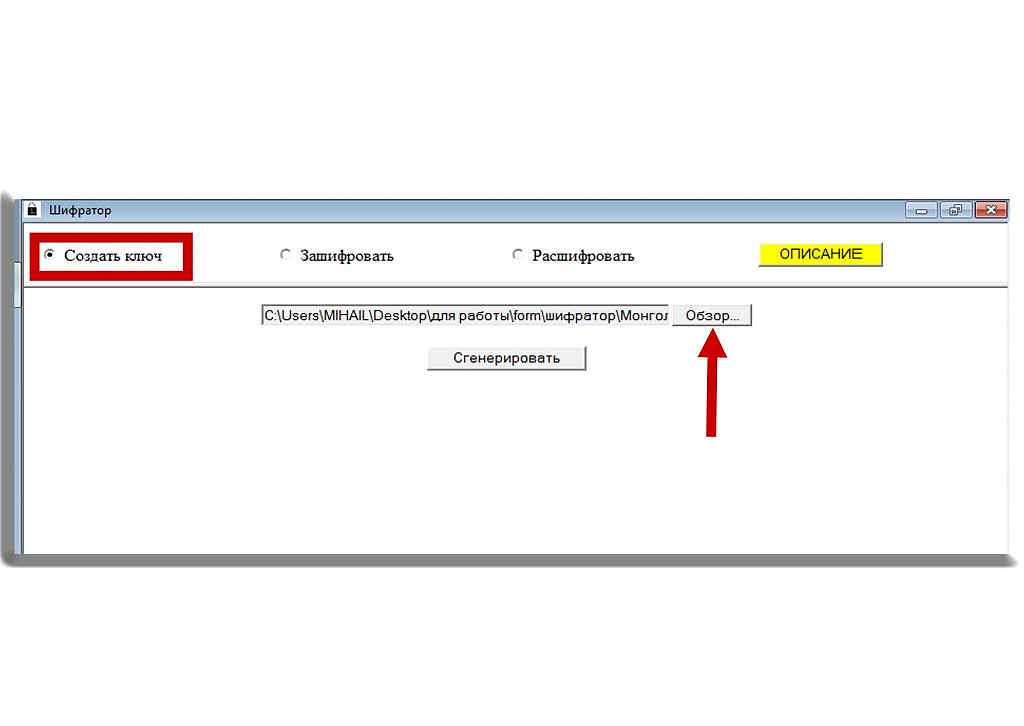
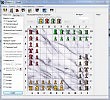
На 1-м рис. показана панель режиима создания ключа. Выбирается текстовый файл, из которого и создается ключ (в случае соответствия выбранного файла указанным требованиям).
Ключ представляет собой таблицу, в которую каждому используемому символу поставлены в соответствие его позиции в выявленной последовательности допустимых символов в файле ключа, длина которой равна точно 65536. Например, фрагмент, начинающийся с "Как, целых 20 минут?!" запишет в таблицу для К 1 и 3 (регистр, понятное дело, не учитывается), для А - 2 и т.д. ("2", "0" и "!" в таблицу не попадут, поскольку не входят в список используемых символов).
Длина ключевой последовательности выбрана такой потому, что номера позиций в ней умещаются ровно в два байта, причем каждому значению соответствует тот или иной символ.
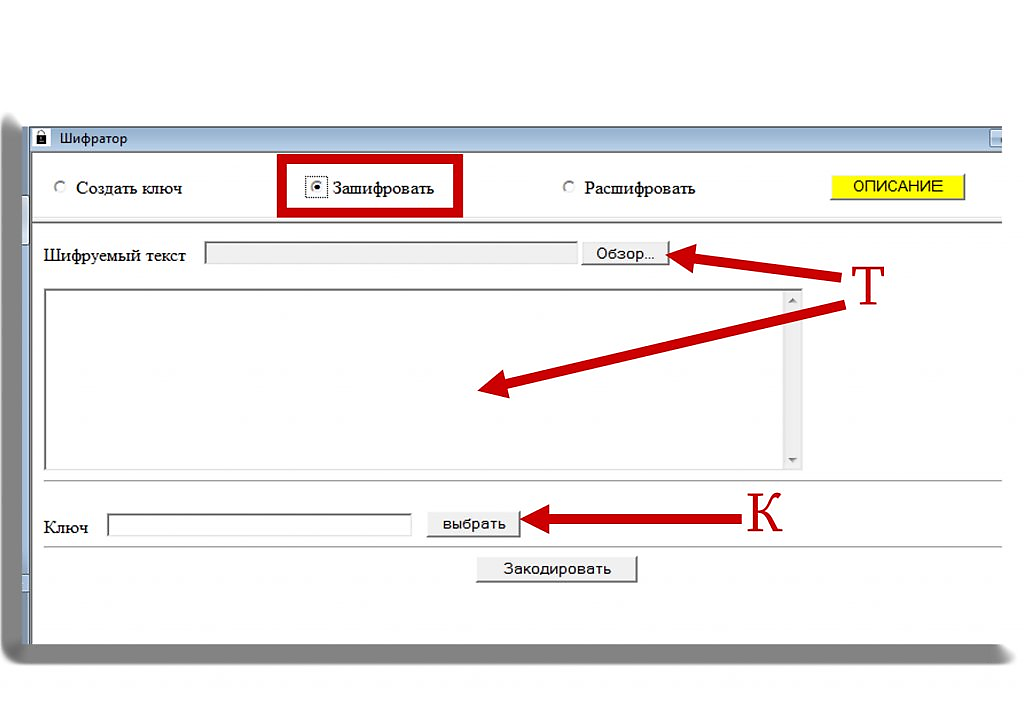
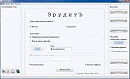
На 2-м рисунке показана панель в режиме зашифровки текста. Текст /Т/ либо выбирается из файла, либо непосредственно вводится в окно; он должен состоять только из определенного выше набора символов плюс некоторых других (например, цифр и восклицательного знака), которые будут просто автоматически переведены в буквы. Выбирается один из заранее подготовленных ключей /К/ и запускается процесс шифрования (в случае обнаружения недопустимых символов будет выдано сообщение об ошибке).
Алгоритм шифрования заключается в том, что каждому символу в тексте случайным образом назначается одно из соответствующих ему значений в ключевой таблице (как в приведенном примере К будут соответствовать 1, 3, ...). Заметим, что ключевая таблица будет заполнена не равномерно, а пропорционально частоте каждой буквы; можно сказать, что ключевая таблица - это проекция статистики текста на отрезок длиной 65536. А произвольный выбор из нее производится, следовательно, с вероятностью, обратно пропорциональной частоте. Таким образом, сам процесс шифрования гасит статистику букв в тексте!
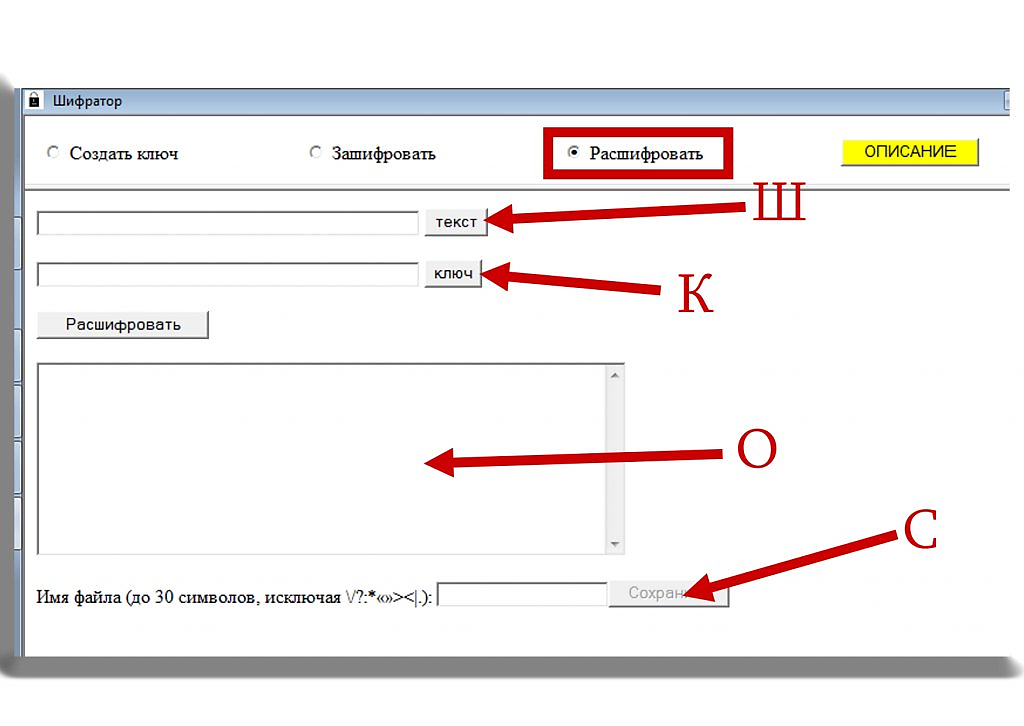
3-й рис. изображает режим расшифровки. Зашифрованный текст /Ш/ помещается в служебный каталог и выбирается для обработки; выбирается и ключ /К/, которым он был зашифрован. Расшифрованный текст /О/ появляется в окне. Он может быть сохранен в файл /С/.
Предлагаемый механизм шифрования имеет то преимущество, что может использовать многочисленные открытые тексты в качестве ключей (например, книги из интернет-библиотек). Поэтому, в частности, корреспонденты могут относительно легко синхронизировать их, указывая на тот или иной источник, сохраняя при этом секретность. Стойкость предлагаемого метода не проверялась и (как и большинства существующих систем) точно неизвестна, но, поскольку сам процесс шифрования гасит статистику текста, она представляется весьма высокой.
_______________________________________________
Попробуем оценить трудоемкость взламывания такого шифра.
Его слабостью является то, что если известен язык написания, то известны и частотные характеристики букв: F(a) для каждого символа a. Алфавит можно упорядочить по частоте F(s(1))≥...≥F(s(n)). F(s(i)) определяет объем символа s(i) в кодовой таблице. Тогда для s(i) потребуется перебор V(i) = C(F(s(i)), 256)+α вариантов, где C(m, n) - число сочетаний, α - довесок "для страховки" (где-то 1 или 2).
Итого, если при гаммировании взлом шифра потребует в худшем случае exp(n, l) переборов (l - длина текста), то для самогасимого шифра потребуется ∏V(i), i=1:n переборов без зависимости от длины текста.
Из этого видно, что теоретически самогасимый шифр гораздо менее стоек гаммирования. Насколько это существенно в плане существующих вычислительных мощностей? Впрочем, размер кодовой таблицы можно расширять и за пределы байта (по степеням 2), так что в конце концов можно будет выбрать параметры, достаточно трудоемкие для существующих на сегодняшний день вычислительных мощностей. Или использовать несколько кодовых таблиц (например, одну для каждого 10-го символа).
И тем не менее, предлагаемый шифр очень удобен в плане генерации ключей. Поэтому он может подойти для обмена ьыстро теряющими актуальность сообщениями в дополнение к гаммированию (чтобы не тратить ресурсы для трудоемкой выработки гамм).
Шифрование невернамовское, т.е. основанное не на наложении на шифруемый текст "гаммы". Предлагаемый принцип шифрования основан на том, что для успешного кодирования достаточно обеспечить однозначность именно раскодирования.
Шифрование начинается с этапа генерации ключа. Для этого выбирается достаточно длинный текст естественного языка, содержащий в себе все используемые символы (в примере это буквы, кроме "ё" и "ъ", поскольку во многих текстах их может просто не быть, а также наиболее часто и потому наверняка содержащиеся в выбранном тексте знаки: пробел " ", точка ".", запятая ",", вопросительный знак "?" и скобки "(" и ")"). Последовательность выявленных используемых символов должна быть не меньше 256×256 = 65536.
На 1-м рис. показана панель режиима создания ключа. Выбирается текстовый файл, из которого и создается ключ (в случае соответствия выбранного файла указанным требованиям).
Ключ представляет собой таблицу, в которую каждому используемому символу поставлены в соответствие его позиции в выявленной последовательности допустимых символов в файле ключа, длина которой равна точно 65536. Например, фрагмент, начинающийся с "Как, целых 20 минут?!" запишет в таблицу для К 1 и 3 (регистр, понятное дело, не учитывается), для А - 2 и т.д. ("2", "0" и "!" в таблицу не попадут, поскольку не входят в список используемых символов).
Длина ключевой последовательности выбрана такой потому, что номера позиций в ней умещаются ровно в два байта, причем каждому значению соответствует тот или иной символ.
На 2-м рисунке показана панель в режиме зашифровки текста. Текст /Т/ либо выбирается из файла, либо непосредственно вводится в окно; он должен состоять только из определенного выше набора символов плюс некоторых других (например, цифр и восклицательного знака), которые будут просто автоматически переведены в буквы. Выбирается один из заранее подготовленных ключей /К/ и запускается процесс шифрования (в случае обнаружения недопустимых символов будет выдано сообщение об ошибке).
Алгоритм шифрования заключается в том, что каждому символу в тексте случайным образом назначается одно из соответствующих ему значений в ключевой таблице (как в приведенном примере К будут соответствовать 1, 3, ...). Заметим, что ключевая таблица будет заполнена не равномерно, а пропорционально частоте каждой буквы; можно сказать, что ключевая таблица - это проекция статистики текста на отрезок длиной 65536. А произвольный выбор из нее производится, следовательно, с вероятностью, обратно пропорциональной частоте. Таким образом, сам процесс шифрования гасит статистику букв в тексте!
3-й рис. изображает режим расшифровки. Зашифрованный текст /Ш/ помещается в служебный каталог и выбирается для обработки; выбирается и ключ /К/, которым он был зашифрован. Расшифрованный текст /О/ появляется в окне. Он может быть сохранен в файл /С/.
Предлагаемый механизм шифрования имеет то преимущество, что может использовать многочисленные открытые тексты в качестве ключей (например, книги из интернет-библиотек). Поэтому, в частности, корреспонденты могут относительно легко синхронизировать их, указывая на тот или иной источник, сохраняя при этом секретность. Стойкость предлагаемого метода не проверялась и (как и большинства существующих систем) точно неизвестна, но, поскольку сам процесс шифрования гасит статистику текста, она представляется весьма высокой.
_______________________________________________
Попробуем оценить трудоемкость взламывания такого шифра.
Его слабостью является то, что если известен язык написания, то известны и частотные характеристики букв: F(a) для каждого символа a. Алфавит можно упорядочить по частоте F(s(1))≥...≥F(s(n)). F(s(i)) определяет объем символа s(i) в кодовой таблице. Тогда для s(i) потребуется перебор V(i) = C(F(s(i)), 256)+α вариантов, где C(m, n) - число сочетаний, α - довесок "для страховки" (где-то 1 или 2).
Итого, если при гаммировании взлом шифра потребует в худшем случае exp(n, l) переборов (l - длина текста), то для самогасимого шифра потребуется ∏V(i), i=1:n переборов без зависимости от длины текста.
Из этого видно, что теоретически самогасимый шифр гораздо менее стоек гаммирования. Насколько это существенно в плане существующих вычислительных мощностей? Впрочем, размер кодовой таблицы можно расширять и за пределы байта (по степеням 2), так что в конце концов можно будет выбрать параметры, достаточно трудоемкие для существующих на сегодняшний день вычислительных мощностей. Или использовать несколько кодовых таблиц (например, одну для каждого 10-го символа).
И тем не менее, предлагаемый шифр очень удобен в плане генерации ключей. Поэтому он может подойти для обмена ьыстро теряющими актуальность сообщениями в дополнение к гаммированию (чтобы не тратить ресурсы для трудоемкой выработки гамм).

Голосование:
Суммарный балл: 10
Проголосовало пользователей: 1
Балл суточного голосования: 0
Проголосовало пользователей: 0
Проголосовало пользователей: 1
Балл суточного голосования: 0
Проголосовало пользователей: 0
Голосовать могут только зарегистрированные пользователи
Вас также могут заинтересовать работы:

Отзывы:
Нет отзывов
Оставлять отзывы могут только зарегистрированные пользователи
Трибуна сайта

Наш рупор